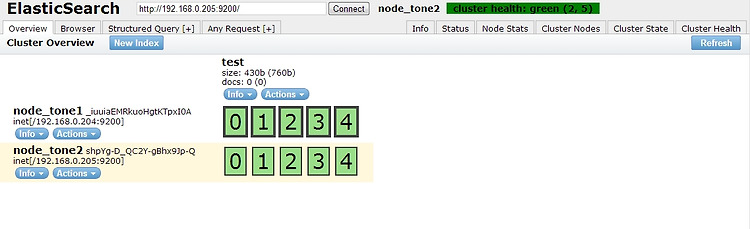
검색엔진 elasticsearch 를 설치하고, 클러스터를 구성하도록 하겠다. (CentOS기준) 우선 하나의 서버에 독립적으로 설치해보자. (http://www.elasticsearch.org/guide/reference/setup/installation.html) elasticsearch (검색엔진) 설치 – 한글형태소분석기 적용 다운로드 받아서 설치 # mkdir -p /data/elasticsearch # mkdir -p /log/elasticsearch # cd /usr/local/src # wget https://github.com/downloads/elasticsearch/elasticsearch/elasticsearch-0.19.12.tar.gz # tar zxvf elasticsearch..
Apache Lucene 프로젝트의 검색 엔진 Solr. Solr Tutorial을 통해 설치를 해보자. 자바 1.5 이상이 설치되어있어야 한다. Solr의 현재 안정버전은 3.6.0이고, 4.0이 개발 중에 있다. # cd /usr/local/src # wget http://ftp.daum.net/apache/lucene/solr/3.6.0/apache-solr-3.6.0.zip # unzip -q apache-solr-3.6.0.zip # cp -Rf apache-solr-3.6.0 /usr/local/solr # cd /usr/local/solr 다운로드 받고, 압축을 풀면 설치는 끝난다. Solr는 모든 자바 서블릿 컨테이너에서 구동이 가능하다 (Tomcat 등..) Solr에는 기본적으로 Jet..